网络层提供主机之间的逻辑通信机制,而传输层提供应用进程之间的逻辑通信机制
3.1 多路复用和多路分用
- 多路复用(发送端):从多个Socket接收数据,为每块数据封装上头部信息,生成Segment,交给网络层
- 多路分用(接收端):传输层依据头部信息将收到的Segment交给正确的Socket,即不同的进程工作方式:
- 主机接收IP数据报:每个数据报携带源IP地址和目的IP地址,还携带一个传输层的段(Segment),每个段携带源端口号和目的端口号
- 收到Segment之后,传输层协议提取IP地址和端口号信息,将Segment导向相应的Socket:网络层不关心端口号信息
3.1.1 无连接的多路分用
- 利用端口号创建Socket
- UDP的Socket用二元组标识:(目的IP地址,目的端口号)
- 主机收到UDP段后检查段中的目的端口号,将UDP段导向绑定在该端口号的Socket,所以只要目的IP和目的端口号相同,来自不同源IP地址和/或源端口号的IP数据包被导向同一个Socket
3.1.2 面向连接的多路分用
TCP的Socket用四元组标识:(源IP地址,源端口号,目的IP地址,目的端口号)
接收端利用所有的四个值将Segment导向合适的Socket
服务器可能同时支持多个TCP Socket,每个Socket用自己的四元组标识:Web服务器为每个客户端开不同的Socket,可能创建多个进程,每个进程一个Socket;也可能创建多个线程,每个线程一个Socket
3.2 无连接传输协议UDP
UDP基于IP协议,解决了复用/分用、简单的错误校验两个问题,UDP协议不可靠,数据可能丢失,可能非按序到达
在应用层增加可靠性机制以实现可靠的数据传输(增加了实现难度)
无连接:UDP发送方和接收方之间不需要握手;每个UDP段的处理独立于其他段
优点:无连接减少了延迟(DNS使用UDP的原因),并且无需维护连接状态因此实现起来也简单;头部开销少;没有拥塞控制,应用可更好地控制发送时间和速率
用途:流媒体应用、DNS、SNMP
UDP报文段格式:
源端口号 目的端口号 UDP段(包含头部)的长度 校验和 应用数据(消息) 校验和checksum
目的:检测UDP段在传输中是否发生错误(如位翻转)
发送方:计算前将校验和字段设为全0,然后将段的内容视为16-bit整数,(校验和计算)计算所有整数的和,进位加在和的后面,将得到的值按位求反,得到校验和;将校验和放入校验和字段
接收方:计算所收到段的校验和,将其与校验和字段进行对比:不相等——检测出错误;相等——没有检测出错误(但可能有错误)
3.3 可靠数据传输
信道的不可靠特性决定了可靠数据传输协议(RDT)的复杂性
3.3.1 可靠数据传输原理
发送方调用
rdt_send()将待发送数据交给可靠数据传输协议可靠数据传输协议调用
udt_send()将数据发送给传输层数据发送到接收方的传输层,调用
rdt_rcv()将数据传给可靠数据传输协议RDT整理后调用
deliver_data将完整的数据发给接收方上层应用
第2、3步的通信都是双向的,以保证传输数据的完整性(可靠性)
3.3.2 RDT
3.3.2.1 RDT1.0
可靠信道上的可靠数据传输协议
假设底层信道完全可靠,无丢失无错误,因此双方无需进行控制信息的传递,发送方只需把消息发送一次即可,接收方收到的消息即是完整的消息。
3.3.2.2 RDT2.0
可能产生位错误的信道上的可靠数据传输协议
利用校验和检测底层信道可能翻转分组中的位错误,双方要进行控制信息的传递以纠正错误:
- ACK (确认机制)——接收方显式地告知发送方分组已正确接收;
- NAK——接收方显式地告知发送方分组有错误,发送方收到NAK后,重传分组
基于这种重传机制的rdt协议称为ARQ(Automatic Repeat reQuest)协议
Rdt 2.0中引入的新机制:差错检测;接收方反馈控制消息: ACK/NAK;重传
在实现的过程中,利用了停-等协议,即发送方发送了一个packet后,只有在收到来自接收方的确认消息后才能继续下一步操作。
3.3.2.3 RDT2.1、2.2
在RDT2.0中没有ACK/NAK消息发生错误/被破坏的处理方案,于是提出了新的解决方案
RDT2.1
如果ACK/NAK坏掉发送方就重传,但这有可能会产生重复分组,所以RDT2.1为每个分组增加了序列号(使用0,1标识——基于停-等协议),所以接收方可以根据序列号丢弃重复分组
相比与2.0,发送方为每个分组增加了序列号,并且需要检验ACK/NAK消息是否发生错误,而且由于状态必须“记住”“当前”的分组,所以序列号FSM的状态数量翻倍;接收方需要判断分组是否重复即是否收到了期望的序列号
RDT2.2:无NAK消息协议
在RDT2.1的基础上删除NAK,接收方通过ACK告知最后一个被正确接收的分组,在ACK消息中显式地加入被确认分组的序列号,发送方收到重复ACK之后,处理方式与收到NAK相同,重传当前分组
3.3.2.4 RDT3.0
如果信道既可能发生错误,也可能丢失分组
在这个协议中,引入了定时器,发送方会等待合理的时间,如果时间内未收到ACK,则重传,而如果分组只是延迟而不是丢了也同样会引发重传,但序列号机制能够处理这种问题
Rdt 3.0能够正确工作,但由于停-等操作规定了需要等待接收方响应之后才进行下一步操作,所以性能很差
3.3.3 滑动窗口协议
3.3.3.1 流水线机制与滑动窗口协议
由于RDT3.0的性能限制在于等待ACK消息的过程中带宽资源闲置,所以在流水线机制下,允许发送方在收到ACK之前连续发送多个分组,因而也需要更大的序列号范围,发送方/接收方需要更大的存储空间以缓存分组
滑动窗口协议 (Sliding-window protocol):窗口是允许的序列号的范围,窗口尺寸为N表示最多有N个等待确认的消息。随着协议的运行,窗口在序列号空间内向前滑动(序列号会越来越大)。
主要的滑动窗口协议:GBN、SR
3.3.3.2 GBN(Go-Back-N)
发送方:分组头部包含k-bit的序列号,窗口尺寸为N,即最多允许N个分组未确认,如果上层应用发来的数据没有可用的序列号时调用refuse_data(data) 拒绝。
ACK(n):确认到序列号n(包含n)的分组均已被正确接收——累积确认
为空中的分组设置计时器(timer),超时Timeout(n)事件:重传序列号大于等于n,还未收到ACK的所有分组
接收方:无缓存,只需要记住唯一的expectedseqnum (期望序列号),对于乱序到达的分组直接丢弃,重新确认序列号最大的、按序到达的分组
ACK机制: 发送拥有最高序列号的、已被正确接收的分组的ACK
3.3.3.3 SR (Selective Repeat)
GBN的丢失信息会导致所有序列号高于已经确认的序列号的包全部重发,因而造成资源浪费。在GBN的基础上改进得SR协议:
发送方只重传那些没收到ACK的分组,为每个分组设置定时器
接收方对每个分组单独进行确认,设置缓存机制,缓存乱序到达的分组,设置一个接收方窗口,将乱序到达的分组缓存,等待前面的分组到达后与前面的分组一起合并和交给上层
- 收到在窗口内的分组时先发送ACK(n),再判断是不是乱序到达的分组,是就缓存,不是就合并交付移动窗口
- 收到窗口左侧的分组发送ACK(n)
- 收到窗口右侧的分组忽略
序列号空间大小与窗口尺寸需满足:N~S~+N~R~<=2^k^
3.4 TCP
3.4.1 TCP段结构
3.4.1.1 TCP段结构
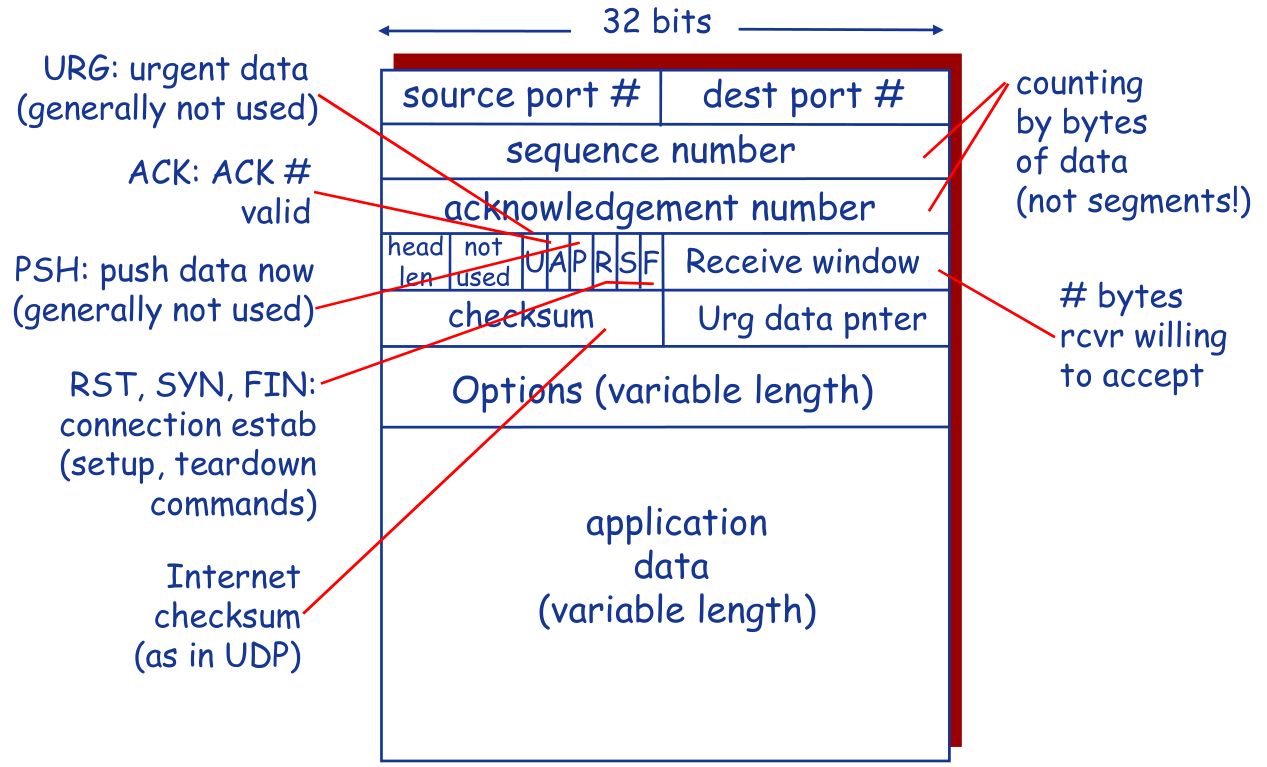
3.4.1.2 序列号
序列号是segment中第一个字节的编号,而不是segment的编号($NextSeqNum = SeqNum + length(data)$)
建立TCP时,双方随机选择序列号
3.4.1.3 ACK
指的是希望接收到的下一个字节的序列号
使用的是累计确认机制(该序列号之前的所有字节均已被正确接收到)
关于乱序到达的Segment,TCP规范中没有规定,由TCP的实现者做出决策
3.4.2 TCP可靠数据传输
TCP在IP层提供的不可靠服务基础上实现可靠数据传输服务,使用了以下机制
流水线机制
累积确认
TCP使用单一重传定时器。触发重传的事件:超时;收到重复ACK
3.4.2.1 RTT和超时
为了设置定时器的超时时间,必须参考网络的RTT时间,而RTT是变化的,所以必须测量RTT
SampleRTT:测量从段发出去到收到ACK的时间。多次测量取平均值得到估计值EstimatedRTT(指数加权移动平均):
$EstimatedRTT = (1- \alpha)EstimatedRTT + \alphaSampleRTT$ ($\alpha$一般取0.125)
超时时间设置为:EstimatedRTT+ 安全边界。所以如果EstimatedRTT变化大就意味着需要设置较大的边界,所以就需要测量RTT的变化值:SampleRTT与EstimatedRTT的差值:
| $DevRTT = (1- \beta)*DevRTT +\beta * | SampleRTT-EstimatedRTT | $ |
所以超时时间的设置:$TimeoutInterval = EstimatedRTT + 4*DevRTT$
3.4.2.2 发送方
从应用层收到数据:创建Segment(设置序列号)–>开启计时器–>设置超时时间:
超时事件:重传引起超时的Segment,重启定时器
收到ACK:如果确认此前未确认的Segment,更新滑动窗口(SendBase),如果窗口中还有未被确认的分组,重新启动定时器。
3.4.2.3 接收方ACK生成
| 接收方事件 | 接收方TCP动作 |
|---|---|
| 收到按序到达的段(之前无等待发ACK的段) | 等待500ms,看是否有下一个段到达,如果没有就直接发送ACK |
| 收到按序到达的段(之前有等待发ACK的段) | 立即发送它的确认消息 |
| 收到乱序到达的段 | 立即发送重复的ACK消息,声明期望的段 |
3.4.2.4 快速重传机制
TCP的实现中,如果发生超时,超时时间间隔将重新设置,即将超时时间间隔加倍,导致其很大,所以重发丢失的分组之前要等待很长时间使之超时。
Sender会连续地发送多个分组,如果某个分组丢失,可能会引发多个重复的ACK,所以可以通过重复ACK检测分组丢失。如果sender收到对同一数据的3个ACK,则假定该数据之后的段已经丢失。
快速重传:在定时器超时之前即进行重传。
问题:为什么是收到3次相同的ACK?
3.4.3 TCP流量控制
接收方为TCP连接分配缓冲区(buffer),而上层应用可能处理buffer中数据的速度较慢,所以就需要流量控制以保证发送方不会传输的太多、太快以至于淹没接收方(buffer溢出)。
流量控制实际上是速度匹配机制。
假定TCP receiver丢弃乱序的段,则Buffer中的可用空间(spare room)= RcvWindow= RcvBuffer-[LastByteRcvd -LastByteRead]
Receiver通过在段的头部字段将RcvWindow 告诉Sender
Sender限制自己已经发送的但还未收到ACK的数据不超过接收方的RcvWindow尺寸
Receiver告知Sender RcvWindow=0,这会导致即使Reciver空闲了也无法通知Sender,所以需要一个机制来使Sender可以发送一个小的段从而可以带回Reciver的信息,避免了上面的死锁。
3.4.4 TCP连接管理
TCP sender和receiver在传输数据前需要建立连接
初始化TCP变量:如分配序列号、分配缓存区、交换流量控制信息。
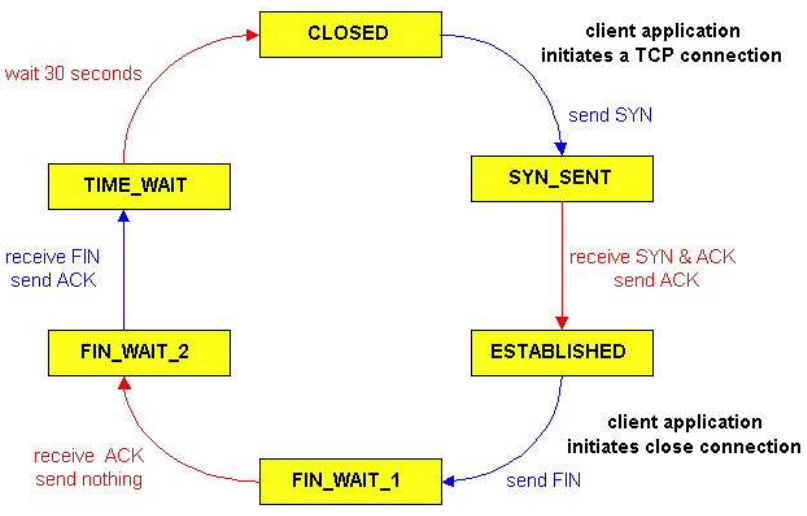
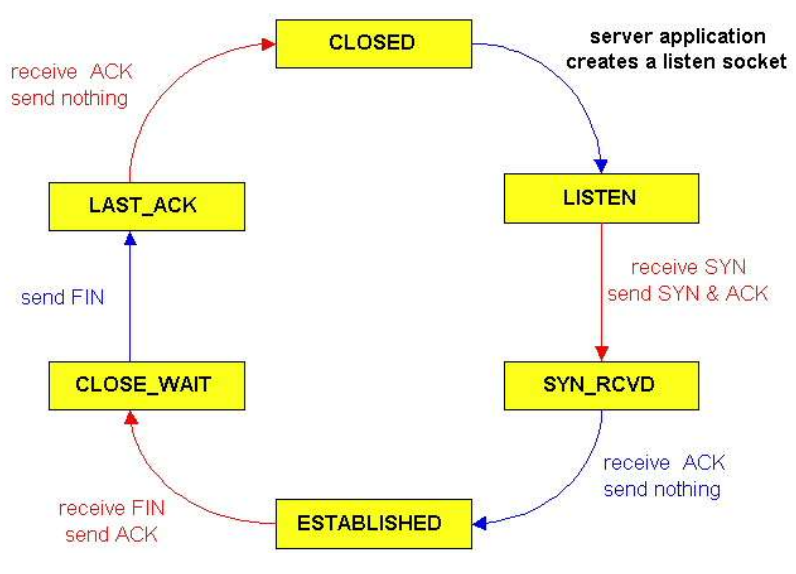
3.4.4.1 TCP建立:三次握手
Client:连接发起者
Server: 等待客户连接请求
Client主机向Server发送一个TCP SYN segment:
SYN=1, seq=client_isn
- 不携带数据
- SYN标志位置1
- 传递选择的初始序列号
Server主机收到SYN,同意建立连接,回复SYNACK段
SYN=1, seq=serever_isn, ack=client_isn+1
- Server分配buffer
- 选择Server端的初始序列号,并告知Client
Client收到SYNACK,答复ACK段,SYN标志不再位置1,也可包含数据。
SYN=0, seq=client_isn+1, ack=server_isn+1
3.4.4.2 TCP关闭
Client和Server都可发起关闭请求,多数是客户机发起。
- Client向server发送TCP FIN 控制segment
- Server收到FIN, 回复ACK. 关闭连接, 发送FIN.
- Client收到FIN, 回复ACK。进入“等待” ——如果收到FIN,会重新发送ACK
- Server收到ACK. 连接关闭.
3.4.4.3 TCP生命周期
TCP客户端:
TCP服务端:
3.5 拥塞控制
拥塞的表现:
- 分组丢失(路由器缓存溢出)
- 分组延迟过大(在路由器缓存中排队)
3.5.1 拥塞的成因和代价
$\lambda_{in}$:实际需要发送的数据
$\lambda’_{in}$:实际需要发送的数据+需要重传的数据
$\lambda_{out}$:实际接收的数据
两个senders,两个receivers,一个路由器且无限缓存:这种条件下不需要重传,但拥塞时分组延迟太大。对于路由器:$\lambda_{in} = \lambda_{out}$
两个senders,两个receivers,一个路由器且有限缓存:可能丢包,所以Sender需要重传分组。对于路由器:
- 情况a:Sender能够通过某种机制获知路由器buffer信息,有空闲才发。$\lambda_{in}=\lambda’{in}=\lambda{out}$
- 情况b:丢失后才重发。$\lambda’{in}>\lambda{out}$
- 情况c:分组丢失和定时器超时后都重发,$\lambda’_{in}$变得更大
由于重传,网络要做更多的工作,造成了资源的浪费。
- 四个发送方,多跳:可能丢包或超时都会引起重传。当拥塞时,一个分组被drop,任何用于该分组的“上游”传输能力全都被浪费掉
3.5.2 拥塞控制的方法
3.5.2.1 端到端拥塞控制
网络层不需要显式的提供支持,端系统通过观察loss,delay等网络行为判断是否发生拥塞。TCP采取这种方法。
3.5.2.2 网络辅助的拥塞控制
路由器向发送方显式地反馈网络拥塞信息,通过简单的拥塞指示(1bit:SNA, DECbit, TCP/IP ECN, ATM)指示发送方应该采取何种速率
3.5.2.3 ATM ABR拥塞控制
**ABR **(available bit rate):
如果发送方路径“underloaded”,使用可用带宽
如果发送方路径拥塞,将发送速率降到最低保障速率
**RM **(resource management) cells:
发送方发送
- 交换机设置RM cell位(网络辅助)
- NI bit: rate不许增长
- CI bit: 拥塞指示
- RM cell由接收方返回给发送方
RM cell中显式的速率(ER)字段:两个字节。拥塞的交换机可以将ER置为更低的值,发送方获知路径所能支持的最小速率
数据cell中的EFCI位:拥塞的交换机将其设为1,如果RM cell前面的data cell的EFCI位被设为1,那么发送方在返回的RM cell中置CI位
3.5.3 TCP拥塞控制
Sender限制发送速率:$LastByteSent-LastByteAcked<= CongWin$,则速率 $rate ≈\frac{CongWin}{RTT}\ Bytes/sec$
CongWin(发送窗口)保证了动态调整以改变发送速率,它反映所感知到的网络拥塞。
感知网络拥塞:Loss事件=timeout或3个重复ACK。发生loss事件后,发送方降低速率。
调整发送速率:加性增—乘性减;慢启动
3.5.3.1 加性增—乘性减: AIMD
原理:逐渐增加发送速率,谨慎探测可用带宽,直到发生loss,一旦发生loss,速率直接减半。
方法: AIMD
Additive Increase:每个RTT将CongWin增大一个MSS——拥塞避免
Multiplicative Decrease:发生loss后将CongWin减半
3.5.3.2 TCP慢启动: SS
原理:当连接开始时,指数性增长——收到每个ACK将CongWin加1 (即每个RTT将CongWin翻倍)。初始速率很慢,但是快速攀升。当CongWin达到Loss事件前值的1/2时,触发拥塞避免机制,指数性增长切换为线性增长。
实现方法:Threshold变量。Loss事件发生时,Threshold被设为Loss事件前CongWin值的1/2,然后开始线性增长。
Loss事件处理
3个重复ACKs:CongWin切到一半然后线性增长
Timeout事件:CongWin直接设为1个MSS,然后指数增长,达到threshold后, 再线性增长。
3个重复ACKs表示网络还能够传输一些 segments,而timeout事件表明拥塞更为严重。
3.5.4 TCP性能分析
TCP吞吐率
忽略掉Slow start,假定发生超时时CongWin的大小为W,吞吐率是W/RTT
超时后,CongWin=W/2,吞吐率是W/2RTT
平均吞吐率为:0.75W/RTT
TCP的公平性
公平:如果K个TCP Session共享相同的瓶颈带宽R,那么每个Session的平均速率为R/K。TCP是公平的。
公平性与UDP:多媒体应用通常不使用TCP,以免被拥塞控制机制限制速率。使用UDP的话可以以恒定速率发送,能够容忍丢失,于是产生了不公平。
公平性与并发TCP连接:某些应用会打开多个并发连接,如Web浏览器,于是产生公平性问题。
例子:链路速率为R,已有9个连接,新来的应用请求1个TCP,获得R/10的速率,新来的应用请求11个TCP,获得R/2的速率